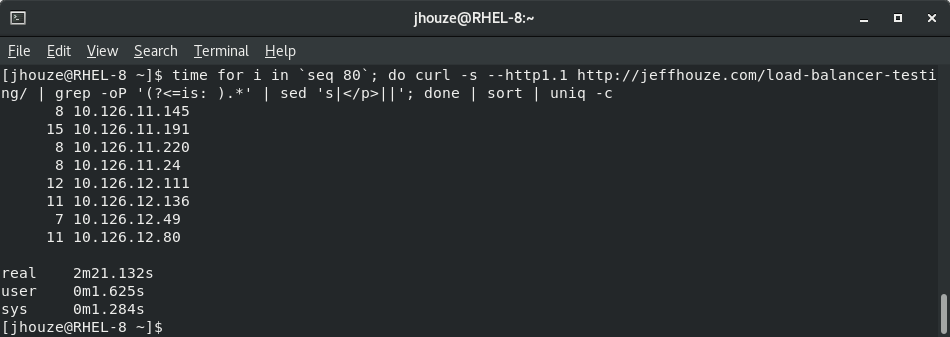
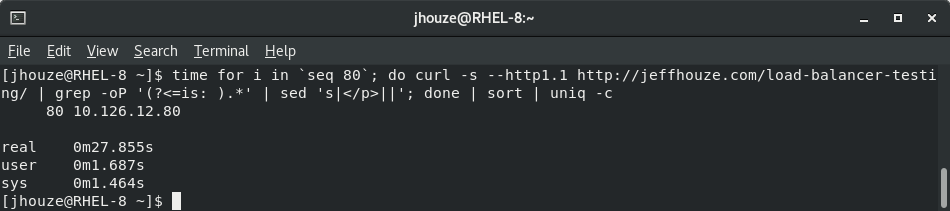
First two images are results of testing with ” Target Tracking scaling” and scraping this page https://jeffhouze.com/load-balancer-testing/ to show the results are from different instances
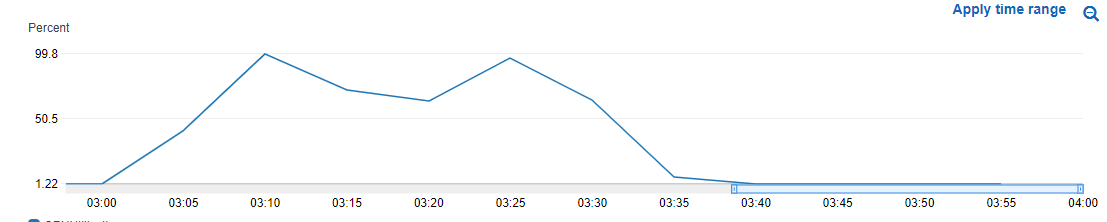
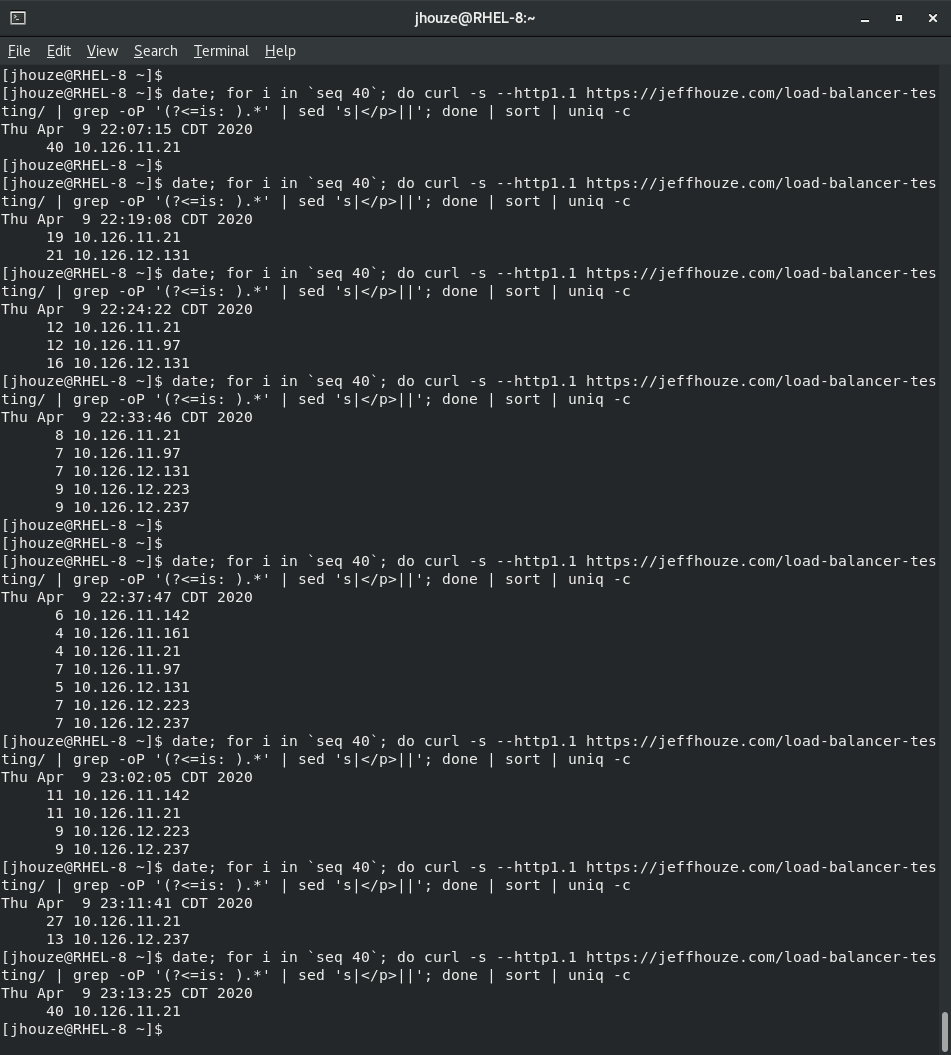
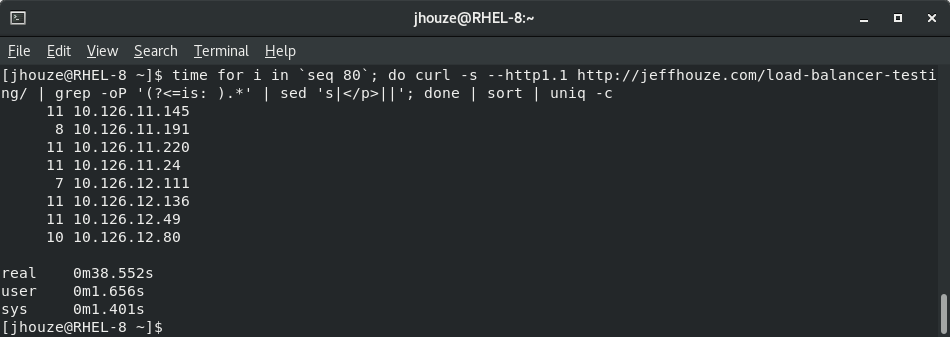
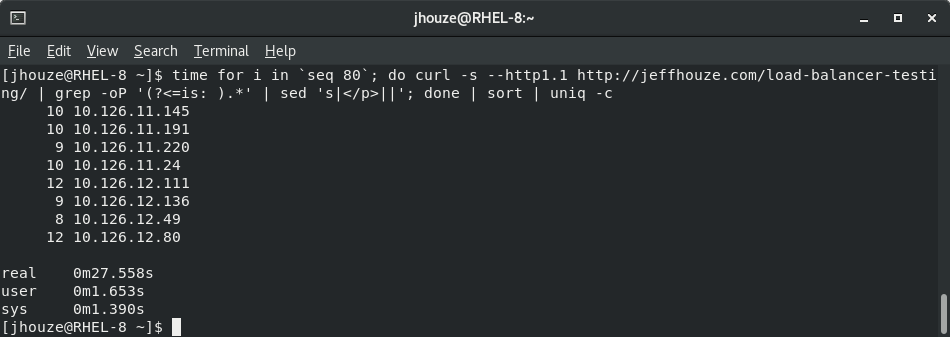
The rest of this page I’m still scraping the same page as above, but illustrating the benefits of a caching plugin, and a unintended side effect.